
はじめに
SQLでデータ分析を始めるとき、集計といえばまず GROUP BY を使います。しかし、次のような高度な分析をしようとしたとき、GROUP BY が壁になります。
- 各社員の売上が、「部門全体の合計」に対して何パーセントか知りたい。
- 地域ごとの売上順位を、元の売上データと同時に一覧表示したい。
これらの分析には、GROUP BY では不可能です。なぜなら、GROUP BY は分析に必要な元の詳細な行の情報を失ってしまうからです。この問題を解決するのが ウィンドウ関数です。
GROUP BYとは?
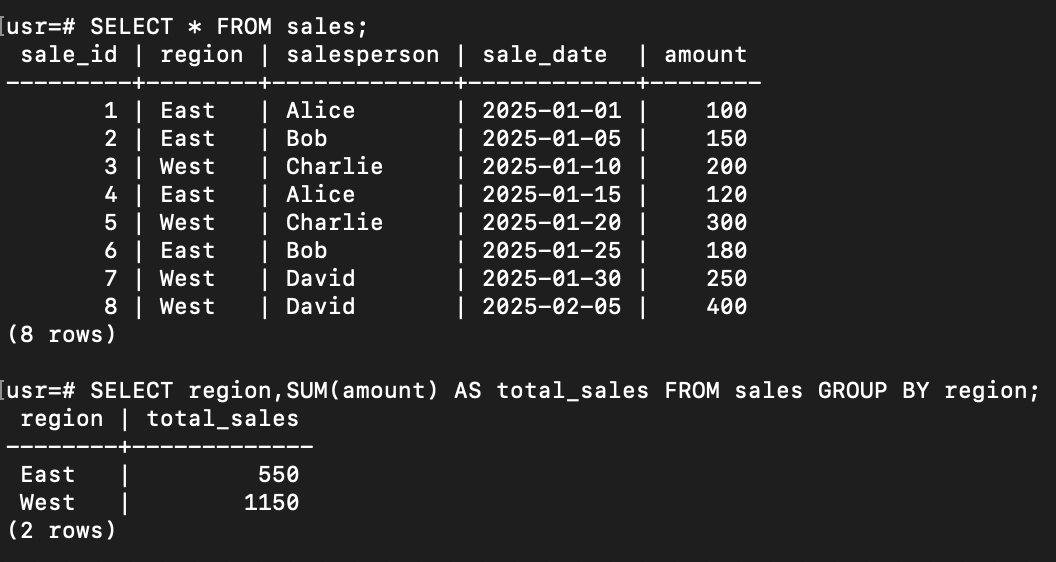
GROUP BY 句は、複数の行を特定の列(例: region)でグループ化し、そのグループに対して集約関数(SUM, AVG, COUNTなど)を適用して一行にまとめる機能です。
- 役割: データを「要約」すること。
- 特徴: 元の行の情報(個別データ)は失われ、集約された結果(例: 地域ごとの合計値)のみが残ります。
HAVING句とは?
HAVING 句は、GROUP BY によって集約されたグループに対して条件を適用し、フィルタリングを行うために使われます。
例: 「合計売上が1000以上の地域」のみを抽出する。

WINDOW関数とは?
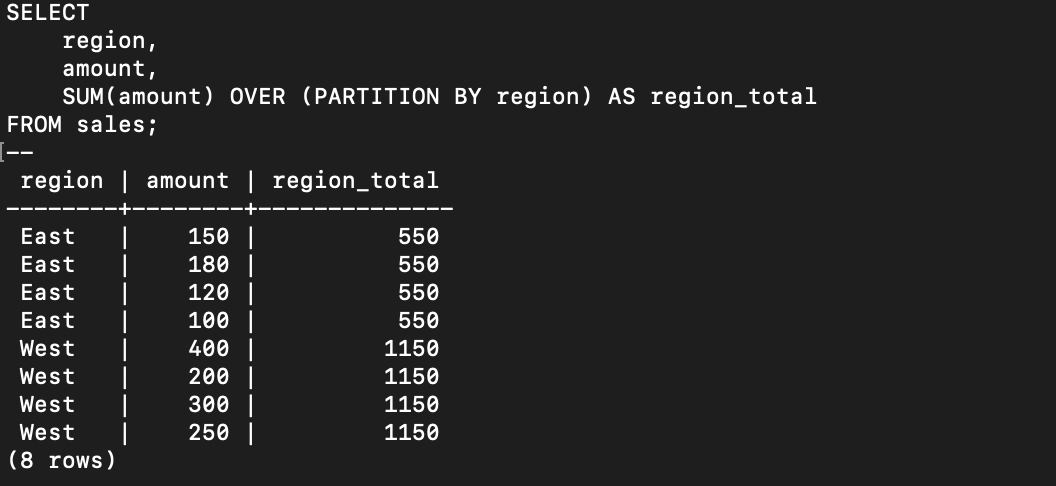
ウィンドウ関数は、OVER 句で定義された行の集合(ウィンドウ)に対して計算を行います。その計算結果は、元の各行に新しい列として付加されます。
- 役割: データを「分析」し、元の行と比較・評価をすること。
- 特徴: 元の行数は維持されます。集計結果は、元の詳細なデータと並べて表示されます。
- 構文: ウィンドウ関数は必ず
OVER句を伴います。
まとめ
GROUP BY とウィンドウ関数の使い分けはシンプルです。
- 行数を減らしてデータを要約したい場合▶︎
GROUP BY - 元の行を残したまま、グループ全体や前後の行と比較・分析したい場合▶︎ウィンドウ関数
ウィンドウ関数を使いこなせば、一度のクエリで詳細データと集約データの両方を扱うことができ、データ分析の幅が格段に広がります。
ありがとうございました✨
