
少子高齢化や財政問題を背景に、平成の大合併は全国で大きな影響を及ぼしました。
では、これからまた合併が起こるとしたら、どの都道府県が「次の候補」になるのでしょうか?
そんな問いに、Pythonと機械学習で迫ってみました。
今回は、こちらのデータをお借りしております。

事前にcsvファイルをダウンロードしておいてください。
よろしくお願いいたします。
 | Pythonで学ぶ はじめてのプログラミング入門教室【電子書籍】[ 柴田 淳 ] 価格:2420円 |
プログラムを作成してみよう
以下が今回作成したプログラムです。
import pandas as pd
from google.colab import files
import io
import datetime
import re
# アップロード:複数CSV(全国分)
uploaded = files.upload()
# CSV読み込み&統合
df_list = []
for fn in uploaded:
df = pd.read_csv(io.BytesIO(uploaded[fn]), encoding='utf-8')
df_list.append(df)
merged_df = pd.concat(df_list, ignore_index=True)
# 変更日を整形(和暦→西暦変換)
def convert_wareki(date_str):
if pd.isna(date_str):
return None
try:
m = re.match(r'(平成|昭和|令和)(\d+)年(\d+)月(\d+)日', date_str)
if m:
era, year, month, day = m.groups()
year = int(year)
month = int(month)
day = int(day)
era_offset = {"昭和":1925, "平成":1988, "令和":2018}
western_year = era_offset[era] + year
return datetime.date(western_year, month, day)
except:
return None
# '変更日'列を変換
merged_df['変更日'] = merged_df['変更日'].map(convert_wareki)
# 合併パターンを自動分類(対等合併 or 吸収合併)
def classify_pattern(df):
result = []
grouped = df.groupby(['変更後', '変更日'])
for (after, date), group in grouped:
if len(group) >= 2:
pattern = "対等合併"
else:
pattern = "吸収合併"
for idx in group.index:
result.append((idx, pattern))
return dict(result)
# 合併パターンを付加
patterns = classify_pattern(merged_df)
merged_df['合併パターン'] = merged_df.index.map(patterns)
# 結果確認
print(merged_df[['変更前', '変更後', '変更日', '合併パターン']].head())from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report
# '変更日'の年と月を特徴量に変換
merged_df['変更年'] = merged_df['変更日'].apply(lambda x: x.year if pd.notna(x) else None)
merged_df['変更月'] = merged_df['変更日'].apply(lambda x: x.month if pd.notna(x) else None)
# '合併パターン'を数値に変換(ラベルエンコーディング)
le = LabelEncoder()
merged_df['合併パターン'] = le.fit_transform(merged_df['合併パターン'])
# 使用する特徴量を選択
features = ['変更年', '変更月']
target = '合併パターン'
# 欠損値を含む行を削除
merged_df = merged_df.dropna(subset=features + [target])
# 特徴量とターゲットのデータセットを分割
X = merged_df[features]
y = merged_df[target]
# 訓練データとテストデータに分割(70%訓練、30%テスト)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# モデルの作成と訓練(ランダムフォレスト)
model = RandomForestClassifier(random_state=42, class_weight='balanced')
model.fit(X_train, y_train)
# 予測と評価
y_pred = model.predict(X_test)
print(classification_report(y_test, y_pred))import matplotlib.pyplot as plt
# 特徴量の重要度を取得
importances = model.feature_importances_
# 特徴量名を取得
feature_names = features
# 特徴量の重要度を降順でソート
indices = importances.argsort()
# 特徴量の重要度をプロット
plt.figure(figsize=(8, 6))
plt.title("Feature Importance")
plt.barh(range(len(features)), importances[indices], align="center")
plt.yticks(range(len(features)), [feature_names[i] for i in indices])
plt.xlabel("Importance")
plt.show()import seaborn as sns
from sklearn.metrics import confusion_matrix
# 混同行列を計算
cm = confusion_matrix(y_test, y_pred)
# 混同行列をヒートマップで表示
plt.figure(figsize=(8, 6))
sns.heatmap(cm, annot=True, fmt="d", cmap="Blues", xticklabels=le.classes_, yticklabels=le.classes_)
plt.title("Confusion Matrix")
plt.xlabel("Predicted")
plt.ylabel("Actual")
plt.show()
# 都道府県名と合併パターンを基に集計
county_merge_pattern = merged_df.groupby(['都道府県', '合併パターン']).size().reset_index(name='count')
# 合併パターンごとの都道府県のランキングを作成
county_merge_pattern = county_merge_pattern.sort_values(by=['count'], ascending=False)
# 合併パターン0と1それぞれについてランキング
county_merge_pattern_0 = county_merge_pattern[county_merge_pattern['合併パターン'] == 0]
county_merge_pattern_1 = county_merge_pattern[county_merge_pattern['合併パターン'] == 1]
print("合併パターン 0 ランキング:")
print(county_merge_pattern_0[['都道府県', 'count']])
print("\n合併パターン 1 ランキング:")
print(county_merge_pattern_1[['都道府県', 'count']])コードの解説
import pandas as pd
from google.colab import files
import io
import datetime
import re
uploaded = files.upload()from google.colab import filesは、Google Colab専用のモジュールで、ローカルファイルをアップロード/ダウンロードする機能を提供します。
たとえば、files.upload()でパソコンからファイルをColabにアップできます
import files import ioは、バイナリストリーム(0/1形式)などを扱うための標準ライブラリです。
アップロードしたファイルをpandasで読み込むときに io.StringIO() を使って中身を読み取ります。
df_list = []空のリスト df_list を作成します。後で読み込んだ DataFrame をここに追加していきます。
for fn in uploaded:uploaded は、アップロードされた複数のファイルを表す辞書のようなオブジェクトです。
fn はそのキー(ファイル名)を1つずつ取り出します。
df = pd.read_csv(io.BytesIO(uploaded[fn]), encoding='utf-8')uploaded[fn] で対応するファイルのバイトデータを取り出します。
io.BytesIO() を使ってバイナリ形式のデータをストリーム(読み取り可能な形式)に変換します。
df_list.append(df)読み込んだ df をリスト df_list に追加します。
merged_df = pd.concat(df_list, ignore_index=True)df_list に入っているすべてのデータフレームを縦にくっつけて、1つのデータフレーム merged_df にします。
ignore_index=True によって、元の行番号を無視して連番に振り直します。
def convert_wareki(date_str):和暦形式の文字列(例:‘令和7年5月2日’)を受け取り、西暦の日付に変換します。
def convert_wareki(date_str):
if pd.isna(date_str):
return Nonedate_str が NaN(欠損値)の場合は None を返して終了します。
try:
m = re.match(r'(平成|昭和|令和)(\d+)年(\d+)月(\d+)日', date_str)
if m:
era, year, month, day = m.groups()
year = int(year)
month = int(month)
day = int(day)
era_offset = {"昭和":1925, "平成":1988, "令和":2018}
western_year = era_offset[era] + year
return datetime.date(western_year, month, day)
except:
return None後続の処理でエラーが出ても止まらず、None を返すようにします。
merged_df['変更日'] = merged_df['変更日'].map(convert_wareki)変更日列を和暦に変換します。
def classify_pattern(df): ここでは、合併パターンを自動分類します df(データフレーム)を引数にとる関数です。
result = []結果を格納するためのリストです。
grouped = df.groupby(['変更後', '変更日'])「どの市町村(例:〇〇市)になったか(=変更後)」と「いつ合併が行われたか(=変更日)」
という2つの軸でグループ化しています。
for (after, date), group in grouped:
if len(group) >= 2:
pattern = "対等合併"
else:
pattern = "吸収合併"
for idx in group.index:
result.append((idx, pattern))
return dict(result)「X市に変更された自治体が、2005-03-22に複数あった」→ 対等合併
「Y市に変更された自治体が、2006-04-01に1件だけ」→ 吸収合併
というように、複数の自治体が同時に1つの市町村になったら「対等合併」、
1つだけなら「吸収合併」と分類します。
patterns = classify_pattern(merged_df) merged_dfをclassify_pattern() に渡して、各レコード(行)の インデックスと合併パターン(対等合併か吸収合併) のペアを取得しています。
戻り値は辞書型: 例){0: ‘吸収合併’, 1: ‘吸収合併’, 2: ‘対等合併’, …}
merged_df['合併パターン'] = merged_df.index.map(patterns)各行のインデックス(0, 1, 2, …)をキーにして、patterns から対応するパターンを取得し、
新しい列 ‘合併パターン’ にその値を追加しています。
print(merged_df[['変更前', '変更後', '変更日', '合併パターン']].head())結果を確認します。
続いて分析パートに入っていきます。
from sklearn.model_selection
import train_test_split
from sklearn.preprocessing import LabelEncoder
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report| ライブラリ | 用途 |
| train_test_split | データを訓練用とテスト用に分割 |
| LabelEncoder | ラベル(文字)を数値に変換(例:“対等合併” → 0, “吸収合併” → 1) |
| RandomForestClassifier | 機械学習モデル:ランダムフォレスト(分類用) |
| classification_report | モデルの精度・再現率などをレポートで表示 |
続いて、’変更日’の年と月を特徴量に変換します。
merged_df['変更年'] = merged_df['変更日'].apply(lambda x: x.year if pd.notna(x) else None)変更日 の値が NaNでなければ(pd.notna(x))、
.year を取り出して ‘変更年’ という列に代入。
merged_df['変更月'] = merged_df['変更日'].apply(lambda x: x.month if pd.notna(x)
else None同じように、 .month を取り出して ‘変更月’ 列に代入。
le = LabelEncoder()LabelEncoder は、カテゴリ(文字列)を整数に変換するクラスです。
例:”対等合併” → 0、”吸収合併” → 1(※順番は自動で決まる)
merged_df['合併パターン'] = le.fit_transform(merged_df['合併パターン'])fit_transform() は次の2つを同時に行います。
- 学習(fit):どんなラベルがあるか把握
- 変換(transform):対応する数字に変換
これにより、合併パターン 列の内容が「0」や「1」といった数値に置き換わります。
features = ['変更年', '変更月']
target = '合併パターン'使用する特徴量を選択します。
merged_df = merged_df.dropna(subset=features + [target])欠損値を含む行を削除します。
X = merged_df[features] y = merged_df[target]特徴量とターゲットのデータセットを分割します。
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)訓練データとテストデータに分割(70%訓練、30%テスト)します。
model = RandomForestClassifier(random_state=42, class_weight='balanced')RandomForestClassifier は 複数の決定木を組み合わせた分類モデル(アンサンブル学習)です。
random_state=42 は 乱数の種を固定して、結果が再現できるようにするものです。
class_weight=’balanced’は クラスの偏り(例:吸収合併が多く、対等合併が少ない)に対処するためのオプション。
自動的に少数クラスの重みを上げて、バランスよく学習させます。
y_pred = model.predict(X_test)
print(classification_report(y_test, y_pred))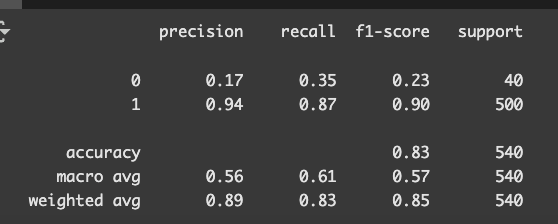
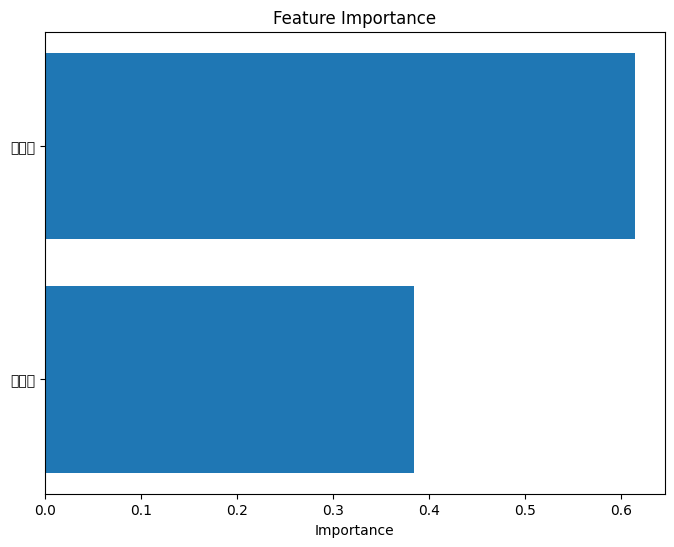
importances = model.feature_importances_ここでは、特徴量の重要度(影響を与えた要素ランキング)を取得しています。
feature_names = features特徴量名を取得します。
indices = importances.argsort()特徴量の重要度を降でソートします。
import matplotlib.pyplot as plt
plt.figure(figsize=(8, 6))
plt.title("Feature Importance")
plt.barh(range(len(features)), importances[indices], align="center") plt.yticks(range(len(features)), [feature_names[i] for i in indices]) plt.xlabel("Importance")
plt.show()特徴量の重要度をプロットします。
import seaborn as sns from sklearn.metrics import confusion_matrix
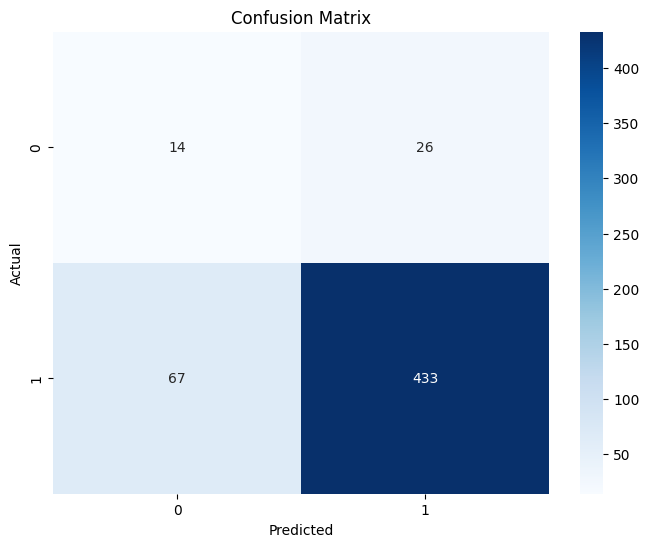
cm = confusion_matrix(y_test, y_pred)混同行列を計算します。
plt.figure(figsize=(8, 6))
sns.heatmap(cm, annot=True, fmt="d", cmap="Blues", xticklabels=le.classes_, yticklabels=le.classes_)
plt.title("Confusion Matrix")
plt.xlabel("Predicted")
plt.ylabel("Actual")
plt.show()混同行列をヒートマップで表示します。
county_merge_pattern = merged_df.groupby(['都道府県', '合併パターン']).size().reset_index(name='count')都道府県名と合併パターンを基に集計します。
county_merge_pattern = county_merge_pattern.sort_values(by=['count'], ascending=False)合併パターンごとの都道府県のランキングを作成します。
county_merge_pattern_0 = county_merge_pattern[county_merge_pattern['合併パターン'] == 0] county_merge_pattern_1 = county_merge_pattern[county_merge_pattern['合併パターン'] == 1]
print("合併パターン 0 ランキング:") print(county_merge_pattern_0[['都道府県', 'count']])
print("\n合併パターン 1 ランキング:") print(county_merge_pattern_1[['都道府県', 'count']])合併パターン0と1それぞれについてランキングを作成します。

合併パターン 0 ランキング:
都道府県 count
76 静岡県 12
14 埼玉県 10
44 愛知県 9
8 北海道 8
74 青森県 8
66 群馬県 7
35 岩手県 7
0 三重県 6
68 茨城県 6
12 和歌山県 6
39 広島県 6
55 石川県 6
72 長野県 6
46 新潟県 5
22 宮崎県 5
26 山口県 4
10 千葉県 4
31 岐阜県 4
60 福岡県 4
37 島根県 4
48 栃木県 4
20 宮城県 3
6 兵庫県 3
62 福島県 3
24 富山県 3
29 山梨県 3
51 滋賀県 3
42 愛媛県 3
4 佐賀県 2
80 高知県 2
64 秋田県 2
82 鳥取県 2
53 熊本県 2
70 長崎県 2
18 大阪府 1
2 京都府 1
16 大分県 1
33 岡山県 1
58 福井県 1
78 香川県 1
84 鹿児島県 1
合併パターン 1 ランキング:
都道府県 count
47 新潟県 83
85 鹿児島県 69
40 広島県 63
32 岐阜県 61
71 長崎県 61
54 熊本県 58
34 岡山県 58
7 兵庫県 56
43 愛媛県 54
65 秋田県 51
30 山梨県 47
69 茨城県 47
61 福岡県 46
73 長野県 45
38 島根県 43
17 大分県 42
21 宮城県 41
1 三重県 40
27 山口県 36
41 徳島県 35
52 滋賀県 35
63 福島県 35
45 愛知県 33
9 北海道 33
5 佐賀県 32
77 静岡県 32
67 群馬県 32
11 千葉県 29
79 香川県 26
81 高知県 25
49 栃木県 25
56 石川県 25
75 青森県 24
83 鳥取県 24
36 岩手県 23
59 福井県 23
3 京都府 22
13 和歌山県 21
15 埼玉県 20
25 富山県 19
50 沖縄県 15
23 宮崎県 14
28 山形県 10
19 奈良県 10
57 神奈川県 4吸収合併型:
静岡・埼玉・愛知のような人口・都市機能が分散した中規模都市圏で吸収型の合併が目立ちます。
地方の自治体再編・都市への統合が進んだ痕跡とも読めます。
統合合併型:
地方部に多い傾向はありますが、都市圏でも合併事例は多く見られます。
特に中山間地域や離島を多く抱える県では、統合型合併が目立ちます。
まとめ
今回は市町村合併の予測についてプログラムを作成しました。
プログラムから結果は出てくれましたが、
クラス1(吸収合併)が 500件、クラス0(対等合併)が 40件 とかなり偏っているため、
モデルが「吸収合併ばかり」と予測してしまう傾向があるように見えます。
次は、より精度を高められるようになりたいです。

コメント