
こんばんは、Yuinaです🌙
これまで取り組んでいたPythonでの機械学習から少し離れて、
今日はデータベースの学習に戻ってきました 📚
今回のテーマは、郵便局データ(latest.csv)などの大量データを、効率よくページ送りする方法についてです。
使用環境は下記のとおりです。
- データベース:MySQL(Ubuntu)
- OS:Mac
- 前提:CSVデータはすでにダウンロード&テーブルへインポート済みです。
それでは、学習スタートします!どうぞよろしくお願いします✨
ページ送りの方法を比較する
ページ送りには主に2つの方法があります。
1つはOFFSET を使った従来のやり方です。
SELECT *
FROM latest_data
ORDER BY city_code
LIMIT 10 OFFSET 1000;しかし、この方法だとMySQLは最初の1000件を一旦読み込んでから捨てるので、大きな OFFSET になるほど遅くなります。
そこでもう1つのINDEXを使ったページ送りを使います。
SELECT * FROM latest_data
WHERE city_code > '01101'
ORDER BY city_code
LIMIT 10;city_codeにインデックスが貼ってあれば、
それを活かして、前回の最後の行のキー値から続きを取得することができます。
「インデックスを貼る」っていうのは、データベースがデータを早く探せるように目次を作ることです。
たとえば、郵便データが電話帳みたいに大量にあるとします。
普通に探すと、最初から1件ずつ見ていく(=全件スキャン)になります。
しかし、「札幌市中央区」だけ欲しい!というときに、
50音順に並んでて、頭文字ごとに目次がついてたら?一気にその場所にジャンプできますよね!
SELECT * FROM latest_data WHERE city_name = '札幌市中央区';↑ このとき、city_nameにインデックスが貼ってあれば、
MySQLは「city_name のインデックスを見て、位置を特定してすぐに取ってくる」ってことができます。
方法について
ここからは、実際にどんなクエリを作成すれば良いのかご紹介していきます。
今回は、前回取得した最後の行の city_code = ‘01101’ で town_name = ‘旭ケ丘三丁目’ の続きから10件取得したい場合を考えていきます。
まず、効率よくデータを探せるように、MySQLに道順を作ります。
CREATE INDEX idx_city_town ON latest_data(city_code, town_name);最初の10件を抽出する場合、以下のクエリを実行します。
SELECT * FROM latest_data ORDER BY city_code, town_name LIMIT 10;表示された最後のデータが、
city_code = '01101'
town_name = '円山西町七丁目'だったとすると、
SELECT * FROM latest_data WHERE (city_code > '01101') OR (city_code = '01101' AND town_name > '円山西町七丁目') ORDER BY city_code, town_name LIMIT 10;この条件のクエリだと、MySQLは:インデックス idx_city_town を使って、
('01101', '円山西町七丁目') より後ろの場所にジャンプして、次の10件を最小のスキャンで取得できます。
どのカラムで絞り込むと一番速くなるかを確かめよう
「どのカラムで絞り込むと一番速いか」を確かめるには、MySQLの実行計画(EXPLAIN)を使うのがベストです。
たとえば、次のようなクエリを試すとします:
EXPLAIN SELECT *
FROM latest_data
WHERE (city_code > '01101')
OR (city_code = '01101' AND town_name > '旭ケ丘十丁目')
ORDER BY city_code, town_name
LIMIT 10;このクエリに対して、EXPLAIN を実行すると
MySQLがどうやってデータを探すか(=インデックスを使ってるかどうかなど)がわかります。
EXPLAINの表で確認すべきポイント(EXPLAINの見方)がこちらです。
| カラム名 | 意味 |
|---|---|
| type | アクセスの方法。index や range が速い。ALL は全件走査で遅い。 |
| key | 使用されているインデックス名。NULLならインデックス使ってない。 |
| rows | MySQLがスキャンすると予測した行数。少ないほど速い。 |
| Extra | Using index や Using where など、追加の情報。 |
実行結果がこちらです。

| 項目 | 意味・説明 |
|---|---|
type: range | 複数の範囲(city_codeとtown_name)にまたがる検索で効率的。 |
key: idx_city_code_town_name | 複合インデックスが使われていて効率的。 |
Extra: Using index condition | インデックスを使った絞り込みで効率的。 |
他にもいろんなカラムで比較してみます。
結果の比較指標
- key に idx_city_town が使われているか?
- type が range や index になっているか?
- rows の値がどれが一番少ないか?
これらを見ることで、「どのカラムでの絞り込みが一番効率的か」が明らかになります。
city_code だけで絞り込み:
EXPLAIN SELECT * FROM latest_data WHERE city_code = '01101' ORDER BY city_code, town_name LIMIT 10;
| 項目 | 意味・説明 |
|---|---|
type: ref | 単一のキー(city_code)に一致する行を探索。 |
key: idx_city_code_town_name | city_codeの条件にtown_nameも並び順として活きてる。 |
rows: 990 | city_code=’01101′ の候補行数。 比較的少ないので高速。 |
Extra: NULL | 単純検索。 |
town_nameだけで絞り込み:
EXPLAIN SELECT * FROM latest_data WHERE town_name > '旭ケ丘十丁目' ORDER BY city_code, town_name LIMIT 10;
| 項目 | 意味・説明 |
|---|---|
type: index | インデックススキャン |
key: idx_city_code_town_name | 並び順が city_code, town_name なので、town_name 単体条件ではちょっと不利。 |
filtered: 50% | 条件に合う行は約半分と予測。無駄スキャンがあるかも。 |
Extra: Using where | WHERE 句であとから条件チェックしてる。 |
city_code + town_name 両方で絞り込み:
EXPLAIN SELECT * FROM latest_data WHERE (city_code > '01101') OR (city_code = '01101' AND town_name > '旭ケ丘十丁目') ORDER BY city_code, town_name LIMIT 10;
| 項目 | 説明 |
|---|---|
type: range | 範囲スキャン。インデックスの一部を使って効率よく走査。 |
key: idx_city_code_town_name | 複合インデックス (city_code, town_name) で効率化。 |
key_len: 446 | 使用しているキーの長さ(=city_code + town_name)が446。全体を活用できてる。 |
rows: 135087 | プランナーの予測行数。多いように見えるけど、インデックスで高速に捌ける。 |
Extra: Using index condition | インデックス上で条件を絞り込みして効率良し。 |
結果を比較してみるとこのようになりました。
4つ目のクエリが最も効率がよさそうです。
| クエリ | 結果 | 効率性 |
|---|---|---|
city_code = ... AND town_name > ... の複合条件 | インデックスが効く | 高速 |
city_code = ... 単体 | 部分インデックス効く | まあまあ速い |
town_name > ... 単体 | インデックス非効率 | 遅め |
| 複合インデックスでページネーション (city_code > x OR (city_code = x AND town_name > y)) | 効率よく次ページ | ベスト |
さらにパフォーマンスを向上させるために
1. 複合インデックスの作成
<table cellpadding="0" cellspacing="0" border="0" style=" border:1px solid #ccc; /*width:300px;*/"><tbody><tr style="border-style:none;"><td style="vertical-align:top; border-style:none; padding:10px; width:87px;"><a href="https://rpx.a8.net/svt/ejp?a8mat=453FFM+DG1FLE+2HOM+BWGDT&rakuten=y&a8ejpredirect=https%3A%2F%2Fhb.afl.rakuten.co.jp%2Fhgc%2Fg00q0724.2bo11c45.g00q0724.2bo12179%2Fa25042272339_453FFM_DG1FLE_2HOM_BWGDT%3Fpc%3Dhttps%253A%252F%252Fitem.rakuten.co.jp%252Fbook%252F17143076%252F%26amp%3Bm%3Dhttp%253A%252F%252Fm.rakuten.co.jp%252Fbook%252Fi%252F20661735%252F%26amp%3Brafcid%3Dwsc_i_is_33f72da33714639c415e592c9633ecd7" rel="nofollow"><img border="0" alt="" src="https://thumbnail.image.rakuten.co.jp/@0_mall/book/cabinet/7278/9784798067278_1_4.jpg?_ex=64x64" /></a></td><td style="font-size:12px; vertical-align:middle; border-style:none; padding:10px;"><p style="padding:0; margin:0;"><a href="https://rpx.a8.net/svt/ejp?a8mat=453FFM+DG1FLE+2HOM+BWGDT&rakuten=y&a8ejpredirect=https%3A%2F%2Fhb.afl.rakuten.co.jp%2Fhgc%2Fg00q0724.2bo11c45.g00q0724.2bo12179%2Fa25042272339_453FFM_DG1FLE_2HOM_BWGDT%3Fpc%3Dhttps%253A%252F%252Fitem.rakuten.co.jp%252Fbook%252F17143076%252F%26amp%3Bm%3Dhttp%253A%252F%252Fm.rakuten.co.jp%252Fbook%252Fi%252F20661735%252F%26amp%3Brafcid%3Dwsc_i_is_33f72da33714639c415e592c9633ecd7" rel="nofollow">Python 実践データ分析 100本ノック 第2版 [ 下山輝昌 ]</a></p><p style="color:#666; margin-top:5px line-height:1.5;">価格:<span style="font-size:14px; color:#C00; font-weight:bold;">2640円</span><br/><span style="font-size:10px; font-weight:normal;">(2025/5/6 12:09時点)</span><br/><span style="font-weight:bold;">感想(1件)</span></p></td></tr></tbody></table>
<img border="0" width="1" height="1" src="https://www13.a8.net/0.gif?a8mat=453FFM+DG1FLE+2HOM+BWGDT" alt="">複合インデックスは、複数のカラムを組み合わせてインデックスを作成する方法です。
これにより、特定の条件での検索が一度のインデックス検索で効率的にできるようになります。
例えば、city_codeとtown_nameでよく検索を行う場合、以下のように複合インデックスを作成できます。
CREATE INDEX idx_city_code_town_name ON latest_data (city_code, town_name);SELECT * FROM latest_data
WHERE city_code, town_name
ORDER BY city_code
LIMIT 10;2. データ量の分割(パーティショニング)
データ量が非常に多い場合、パーティショニングを使用してテーブルを分割することで、
特定の範囲に対するクエリのパフォーマンスを向上させることができます。
パーティショニングは、テーブルを物理的に複数の部分に分けて管理する方法です。
ALTER TABLE latest_data PARTITION BY RANGE (pref_code) ( PARTITION p01 VALUES LESS THAN (10), PARTITION p02 VALUES LESS THAN (20), PARTITION p03 VALUES LESS THAN (30), PARTITION p04 VALUES LESS THAN (40), PARTITION p05 VALUES LESS THAN (50) );SELECT table_name, partition_name, table_rows FROM information_schema.partitions WHERE table_name = 'latest_data';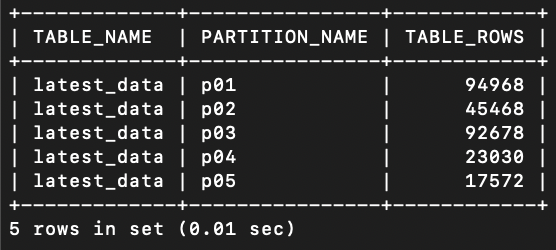
パフォーマンスが向上しているか確認しよう
効率が良くなってるかどうか確認するには、
以下の方法で パーティションが正しく使われているか&インデックスが効いているか をチェックできる
EXPLAIN SELECT * FROM latest_data WHERE pref_code = 1;
select * from latest_data where partitions = 'p01';
この出力の中にpartitionカラムにp01が出てくる場合、
パーティションテーブルとして正しく使われている証拠です!
SHOW TABLE STATUS LIKE 'latest_data';パーティション化されているかをざっくり確認することも可能です。

#クエリの実行時間を計測(MySQLのプロンプト上)
SELECT * FROM latest_data WHERE pref_code = 1;
#クエリ前にこのコマンドで表示できるようにする
SET PROFILING = 1;
#実行後にこれで確認
SHOW PROFILES;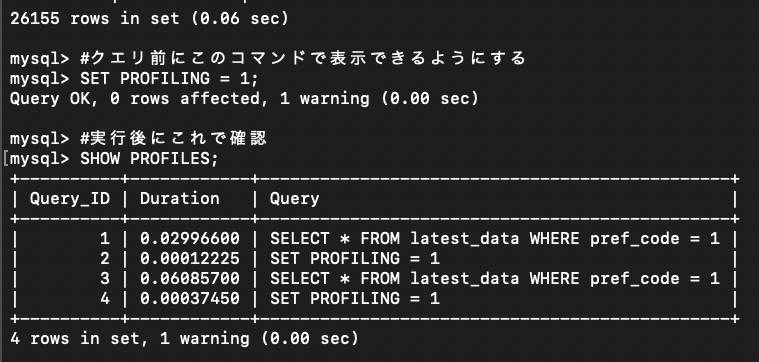
カラムの意味は下記のとおりです。
Query_ID:実行した順番
Duration:そのクエリにかかった秒数
Query:その内容
ID1を見ると、0.02秒くらいで処理できていて、パフォーマンス良好です!
深掘り編
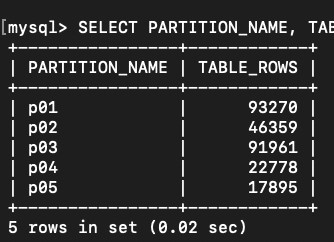
どのパーティションが使われたか確認するには下記を用います。
EXPLAIN SELECT * FROM latest_data WHERE pref_code = 1;ここで partition カラムに p01と表示されれば、狙った分割がちゃんと使われてます。
SELECT PARTITION_NAME, TABLE_ROWS FROM information_schema.PARTITIONS WHERE TABLE_NAME = 'latest_data';これで、どのパーティションにどれくらいの行が入っているか確認できます。
まとめ
最初に紹介した郵便局データのページ送りのクエリを例に、今回の内容を振り返っていきます。
SELECT * FROM latest_data
WHERE city_code > '01101'
ORDER BY city_code
LIMIT 10;→FROMはパーティショニング(データ分割)が効いてると、「pref_codeが1ならp01のパーティションだけ読む」みたいに、読みに行く対象のデータ範囲が一部に限定されます!
→WHEREのcity_codeにインデックスがあると、全件読まずに、01101より後の位置にジャンプして、必要なデータだけピックアップできます!
→ORDER BYのcity_codeにインデックスがあると、すでに並んでる状態でアクセスできるため、並べ替えの追加コストがほぼゼロです!
→LIMITは最初からインデックスで飛んでLIMITで止まるのでめっちゃ速いです!
ありがとうございました。

コメント