
こんにちは、Yuinaです!
今日は晴れていて、4月ですが半袖で過ごしています。皆さん、いかがお過ごしでしょうか?
さて、以前の投稿で決定木を使って体調の未来予測について触れましたが、今回は少しアプローチを変えて、文字データ(コメント)を活用して分析していこうと思います。
前回は日記の数値データ(気温や頭痛の有無など)を使っていましたが、今回は文字データを加えて予測を進めていきます。
環境は以下の通りです🪚
OS:Mac
言語:Python 3.12(myenv)
よろしくお願いします!
感情分析をしよう
テキストから感情を抽出するタスクを「感情分析」といいます。
今日は、感情分析を使って日記の「コメント」を分析していきます。
使用するPythonのライブラリはtorchとtransformerです。
import torch
from transformers import pipeline, AutoModelForSequenceClassification, AutoTokenizer
# 事前学習済みの日本語感情分析モデルとそのトークナイザをロード
model = AutoModelForSequenceClassification.from_pretrained('christian-phu/bert-finetuned-japanese-sentiment')
tokenizer = AutoTokenizer.from_pretrained('christian-phu/bert-finetuned-japanese-sentiment', model_max_lentgh=512)
# 感情分析のためのパイプラインを設定
nlp = pipeline('sentiment-analysis', model=model, tokenizer=tokenizer, truncation=True)
texts = ["嬉しい","悲しい"]
# 各テキストに対して感情分析を実行
for text in texts:
print('*'*50)
inputs = tokenizer(text, padding=True, truncation=True, return_tensors='pt', max_length=512)
outputs = model(**inputs)
logits = outputs.logits
# ロジットを確率に変換
probabilities = torch.softmax(logits, dim=1)[0]
# ロジットを確率に変換
probabilities = torch.softmax(logits, dim=1)[0]
# 最も高い確率の感情ラベルを取得
sentiment_label = model.config.id2label[torch.argmax(probabilities).item()]
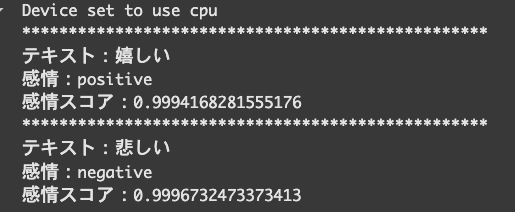
print('テキスト:{}'.format(text))
print('感情:{}'.format(sentiment_label))
# positiveまたはnegativeの場合はその確率を表示、neutralの場合はpositiveとnegativeの最大値を表示
if ((sentiment_label == 'positive') or (sentiment_label == 'negative')):
print('感情スコア:{}'.format(max(probabilities)))
else:
print('感情スコア:{}'.format(max(probabilities[0], probabilities[2])))「嬉しい」の言葉に対して、POSITIVE(前向き)の判定結果が返ってきました。
「悲しい」の言葉に対して、NEGATIVE(消極的)の判定結果が返ってきました。
この仕組みを使って、日記のコメントでは、POSITIVEを1、NEGATIVEを-1、NATURALを0と数値化します。
import torch
from transformers import pipeline, AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained('christian-phu/bert-finetuned-japanese-sentiment')
tokenizer = AutoTokenizer.from_pretrained('christian-phu/bert-finetuned-japanese-sentiment', model_max_length=512)
# 感情分析のためのパイプラインを設定
nlp = pipeline('sentiment-analysis', model=model, tokenizer=tokenizer, truncation=True)
texts = ["嬉しい","悲しい"]
# 各テキストに対して感情分析を実行
for text in texts:
print('*'*50)
inputs = tokenizer(text, padding=True, truncation=True, return_tensors='pt', max_length=512)
outputs = model(**inputs)
logits = outputs.logits
# ロジットを確率に変換
probabilities = torch.softmax(logits, dim=1)[0]
# 最も高い確率の感情ラベルを取得
sentiment_label = model.config.id2label[torch.argmax(probabilities).item()]
# positive、negative、neutral をラベルに変換
if sentiment_label == 'positive':
label = 0
elif sentiment_label == 'negative':
label = -1
else: # 'neutral'
label = 0 # または必要に応じて、neutralをどう扱うか決める
print('テキスト:{}'.format(text))
print('感情ラベル:{}'.format(label))
print('感情スコア:{}'.format(max(probabilities)))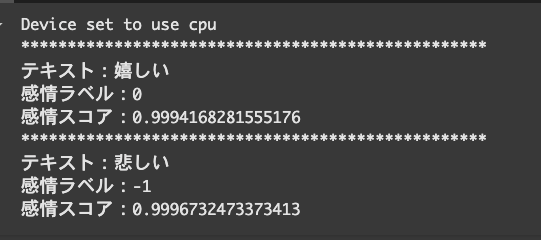
上記のコード解説
from transformers import pipeline, AutoModelForSequenceClassification, AutoTokenizertransformers ライブラリ(Hugging Face)を使います。
事前に学習された日本語モデル(BERTベース)をロードします。
model = AutoModelForSequenceClassification.from_pretrained('christian-phu/bert-finetuned-japanese-sentiment')
tokenizer = AutoTokenizer.from_pretrained('christian-phu/bert-finetuned-japanese-sentiment', model_max_length=512)from_pretrained()は、ネット上からモデルをダウンロードしてロードする関数です。
model_max_length=512は、一度に処理できる最大トークン数です。
nlp = pipeline('sentiment-analysis', model=model, tokenizer=tokenizer, truncation=True)pipeline() は Hugging Face が提供する簡易ラッパーで、感情分析を手軽にできます。
簡易ラッパーとは、難しい操作を簡単にするための道具です。(例:車を運転する時に「ギアを入れる」「クラッチを踏む」といった手順があるけど、オートマ車だとその操作が簡単になっているみたいな)。
texts = ["嬉しい", "悲しい"]
# 各テキストに対して感情分析を実行
for text in texts:
print('*'*50)
inputs = tokenizer(text, padding=True, truncation=True, return_tensors='pt', max_length=512)textsにテキストデータをリストで用意します。
textをBERT が読める形式に変換しています。
tokenizerを使用して入力テキストをトークンに変換していますが、
その際に、どの形式で結果を返すかを指定できます。
return_tensors='pt'と指定すると、出力はPyTorchのテンソル形式(2次元)になります。
outputs = model(**inputs)
logits = outputs.logitsinputsは、トークナイザーを使って入力テキスト(例えば「嬉しい」)をトークン化し、テンソルに変換したデータです。
model(**inputs)は、モデルにその入力データを渡します。
**inputs の意味は、辞書形式のinputsを展開して(inputsにはinput_idsやattention_maskが含まれている)、modelに渡すことです。
outputsは、モデルは入力を基に予測を行い、その結果を返します。
この予測結果がoutputsです。
outputsにはモデルの出力が含まれており、その中にはロジット(logits)という値が含まれています。
これが感情分類などのタスクの予測スコアです。
これは3クラス(左からネガティブ・ナチュラル・ポジティブ)に対するスコアです。
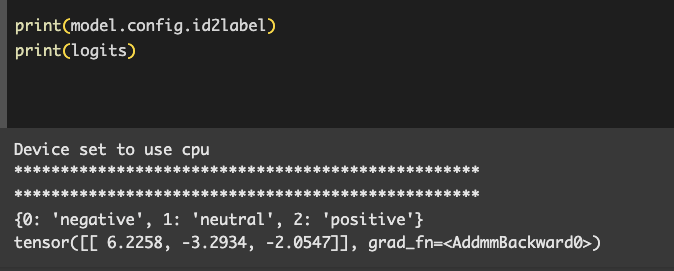
→ 一番高いスコアは negative(0番)
つまり、これは 「ネガティブ」な感情だとモデルが判断している ということになります。
⭐️ロジット(logits)は生のスコアなので、これを確率に変換する必要があります。
そのために、torch.softmaxを使って確率に変換します。
softmaxは、これらのスコアを0から1の範囲の確率に変換してくれます。
probabilities = torch.softmax(logits, dim=1)
print(probabilities)
probabilities はlogitsと同様、 [negativeの確率, neutralの確率, positiveの確率] みたいな形のリストになっています。
sentiment_label = model.config.id2label[torch.argmax(probabilities).item()]torch.argmax(probabilities) は、この中で一番大きい値があるインデックス)を教えてくれます。
.item() でそれを普通の数字に変えてくれます(PyTorchの型→Pythonのint型に変換)。
ここまでの流れですが、例えば以下のコードなら
probabilities = tensor([0.98, 0.01, 0.01])これは [negative, neutral, positive] の順なので、
一番高い 0.98 → index=0 → id2label[0] → ‘negative’ が返される。
という流れで処理が行われます。
プログラムを作成しよう
ここからは実際にプログラムを作っていきます。
import torch
from transformers import pipeline, AutoModelForSequenceClassification, AutoTokenizer
# 事前学習済みの日本語感情分析モデルとそのトークナイザをロード
model = AutoModelForSequenceClassification.from_pretrained('christian-phu/bert-finetuned-japanese-sentiment')
tokenizer = AutoTokenizer.from_pretrained('christian-phu/bert-finetuned-japanese-sentiment', model_max_length=512)
# 感情分析のためのパイプラインを設定
nlp = pipeline('sentiment-analysis', model=model, tokenizer=tokenizer, truncation=True)
texts = [
"新しい洋服を買えて、嬉しい",
"ジムに行って筋トレできるくらい元気だった",
"強い日差しで頭が痛い",
"昨日の疲れもあり帰宅後3時間お昼寝した",
"勉強が盛り上がって楽しかった",
"嬉しいことがあったため、今週1番テンション高かった",
"今日は久しぶりの雨で体調崩した",
"風邪を引いて苦しい",
"ジムで体を動かしてリフレッシュできた",
"勉強に集中できなかった",
"体がだるかったが少し運動して気分転換した",
"勉強が順調で、やる気が少しずつ戻ってきた",
"勉強に集中できた",
"気分も安定していて、軽い運動もできてよかった",
"生理と疲労が重なり、頭痛もあって辛い一日だった",
"仕事や運動もこなせて、気持ち的にも落ち着いていた",
"強い頭痛とだるさで、ほぼ一日中横になっていた",
"軽く体を動かしたが、疲れが取れきれない感じだった",
"勉強が進み、達成感があって良い一日だった",
"睡眠はやや短めだったが、安定して過ごせた",
"気分が良く、軽い運動や仕事もスムーズにできた",
"疲労感が強く、体も重く感じた一日だった",
"睡眠がしっかり取れて、少し元気を取り戻した",
"強い日差しと体調不良で、だるさが続いた",
"少し疲れはあったが、ゆったり過ごせた",
"睡眠が浅かったが、勉強はなんとか進めた",
"安定して過ごせたが、疲れが少し残った",
"気分も体調も安定して、スムーズに動けた",
"疲れと体調不良が重なり、辛い一日だった",
"今日は元気だった"
]
labels = []
# 各テキストに対して感情分析を実行
for text in texts:
# print('*'*50)
inputs = tokenizer(text, padding=True, truncation=True, return_tensors='pt', max_length=512)
outputs = model(**inputs)
logits = outputs.logits
# ロジットを確率に変換
probabilities = torch.softmax(logits, dim=1)[0]
# 最も高い確率の感情ラベルを取得
sentiment_label = model.config.id2label[torch.argmax(probabilities).item()]
if sentiment_label == 'positive':
labels.append(0)
elif sentiment_label == 'negative':
labels.append(-1)
else: # neutralの場合
labels.append(1)
print('テキスト:{}'.format(text))
print('感情ラベル:{}'.format(label))
print('感情スコア:{}'.format(max(probabilities)))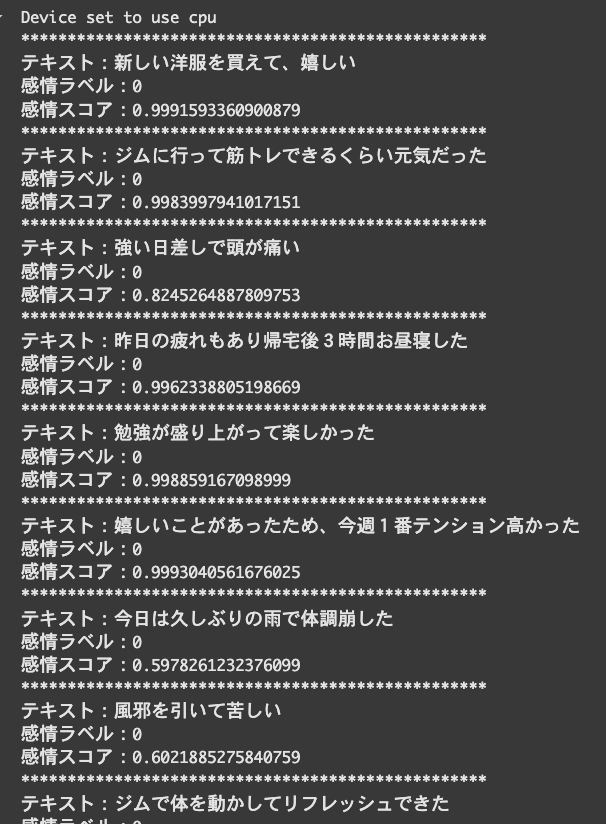
先ほどと同様に、感情分析で出てきたPOSITIVE,NEGATIVE,NATURALを数値化しています。
ここに気温や気分など他のデータを足していきます。
データの詳細はこちらの記事をご覧ください。
import torch
import pandas as pd
from transformers import pipeline, AutoModelForSequenceClassification, AutoTokenizer
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report
import numpy as np
# 事前学習済みの日本語感情分析モデルとそのトークナイザをロード
model = AutoModelForSequenceClassification.from_pretrained('christian-phu/bert-finetuned-japanese-sentiment')
tokenizer = AutoTokenizer.from_pretrained('christian-phu/bert-finetuned-japanese-sentiment', model_max_length=512)
# 感情分析のためのパイプラインを設定
nlp = pipeline('sentiment-analysis', model=model, tokenizer=tokenizer, truncation=True)
texts = [
"新しい洋服を買えて、嬉しい",
"ジムに行って筋トレできるくらい元気だった",
"強い日差しで頭が痛い",
"昨日の疲れもあり帰宅後3時間お昼寝した",
"勉強が盛り上がって楽しかった",
"嬉しいことがあったため、今週1番テンション高かった",
"今日は久しぶりの雨で体調崩した",
"風邪を引いて苦しい",
"ジムで体を動かしてリフレッシュできた",
"勉強に集中できなかった",
"体がだるかったが少し運動して気分転換した",
"勉強が順調で、やる気が少しずつ戻ってきた",
"勉強に集中できた",
"気分も安定していて、軽い運動もできてよかった",
"生理と疲労が重なり、頭痛もあって辛い一日だった",
"仕事や運動もこなせて、気持ち的にも落ち着いていた",
"強い頭痛とだるさで、ほぼ一日中横になっていた",
"軽く体を動かしたが、疲れが取れきれない感じだった",
"勉強が進み、達成感があって良い一日だった",
"睡眠はやや短めだったが、安定して過ごせた",
"気分が良く、軽い運動や仕事もスムーズにできた",
"疲労感が強く、体も重く感じた一日だった",
"睡眠がしっかり取れて、少し元気を取り戻した",
"強い日差しと体調不良で、だるさが続いた",
"少し疲れはあったが、ゆったり過ごせた",
"睡眠が浅かったが、勉強はなんとか進めた",
"安定して過ごせたが、疲れが少し残った",
"気分も体調も安定して、スムーズに動けた",
"疲れと体調不良が重なり、辛い一日だった",
"今日は元気だった"
]
labels = []
# 各テキストに対して感情分析を実行
for text in texts:
# print('*'*50)
inputs = tokenizer(text, padding=True, truncation=True, return_tensors='pt', max_length=512)
outputs = model(**inputs)
logits = outputs.logits
# ロジットを確率に変換
probabilities = torch.softmax(logits, dim=1)[0]
# 最も高い確率の感情ラベルを取得
sentiment_label = model.config.id2label[torch.argmax(probabilities).item()]
if sentiment_label == 'positive':
labels.append(1)
elif sentiment_label == 'negative':
labels.append(-1)
else: # neutralの場合
labels.append(0)
# print('テキスト:{}'.format(text))
# print('感情ラベル:{}'.format(label))
# print('感情スコア:{}'.format(max(probabilities)))
data = {"コメント(気分)": labels,
"日付": [
"4/17", "4/18", "4/19", "4/20", "4/21",
"4/22", "4/23", "4/24", "4/25", "4/26",
"4/27", "4/28", "4/29", "4/30", "5/1",
"5/2", "5/3", "5/4", "5/5", "5/6",
"5/7", "5/8", "5/9", "5/10", "5/11",
"5/12", "5/13", "5/14", "5/15", "5/16"],
"気温": [
25, 25, 27.8, 23.7, 23.3, 23.2, 17, 25, 25, 27.8,
23.7, 23.3, 23.2, 17, 25, 25, 27.8, 23.7, 23.3, 23.2,
17, 25, 25, 27.8, 23.7, 23.3, 23.2, 17, 25, 25],
"睡眠時間": [
7, 7, 5, 9, 8, 8, 7, 7, 5, 9,
8, 8, 6.5, 7, 7, 5, 9, 8, 8, 7,
7, 5, 9, 8, 8, 6.5, 7, 7, 5, 9],
"体調不良": [
0, 1, 1, 0, 0, 0, 1, 1, 0, 0,
0, 1, 1, 0, 0, 0, 1, 1, 0, 0,
0, 1, 1, 0, 0, 0, 1, 1, 0, 0,]
}
# DataFrameに変換
df = pd.DataFrame(data)
df
以下は、現在のデータフレームの状態です。
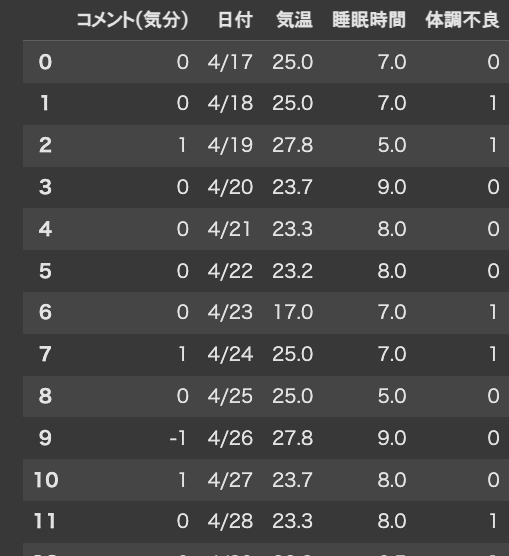
続きを書いていきます。
# 特徴量とターゲットを再度分ける
X = df[['コメント(気分)','気温', '睡眠時間']]
y = df['体調不良']Xに予測に使いたい特徴量(変数)を指定しています。
コメント(気分), 睡眠時間, 気温の3つの特徴量を使っています。
y = df[‘体調不良’]は、予測したいターゲット(出力データ)である 「体調不良」を指定しています。
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.1, random_state=42)train_test_split は、データをトレーニングセット(モデルを学習させるためのデータ)とテストセット(モデルの精度を評価するためのデータ)に分割します。
test_size=0.1で、全体の10%をテストデータ、残り90%をトレーニングデータとして使用することを指定しています。
random_state=42 は乱数のシード値を指定しており、これによって同じデータ分割を再現できるようにしています。
# ランダムフォレスト
#訓練するデータをモデルに入れる
model = RandomForestClassifier(random_state=42)
#訓練の実行
model.fit(X_train, y_train)「決定木」のアルゴリズムをたくさん作って(数百本とか)それぞれにデータの一部だけを見せて学習させて(バラバラの視点を持たせる)、最後に全体の予測を平均したり多数決したりして結果を出す感じです。
イメージは、例えば「今日は傘を持って行くべきか?」を決めるときに:
- Aさん:「天気予報が雨なら傘持っていこう」
- Bさん:「湿度が高い日は持つ」
- Cさん:「風が強い日は持たない」
- Dさん:「前日に雨なら今日も傘持つ」
…といろんな人が自分のルール(=決定木)で判断して、 最後に多数決で「今日は持つ」or「持たない」と決めるイメージです。
# 予測と評価
y_pred = model.predict(X_test)ランダムフォレストモデルで訓練後のモデルをy_predに格納します。
続いて、体調の良し悪しに影響をもたらす要素を分析するプログラムを書いていきます。
# 特徴量の重要度を取得
importances = model.feature_importances_feature_importances_という変数を、modelに付与します。
feature_importances_は、各特徴量をそれぞれどのくらいの重要度で利用したかがわかるものです。
# 特徴量の名前と重要度をまとめる
feature_importance = pd.DataFrame({
'特徴量': X.columns,
'重要度': importances
})feature_importanceに特徴量(コメント(気分),気温,睡眠時間のカラム)を格納します。
重要度には、importances(特徴量の重要度を取得するための変数)を入れます。
# 重要度が高い順に並べる
feature_importance = feature_importance.sort_values(by='重要度', ascending=False)
print(feature_importance)
# 結果表示
print(classification_report(y_test, y_pred))最後に重要度が高い順にソートして、表示します。
結果このようになりました。
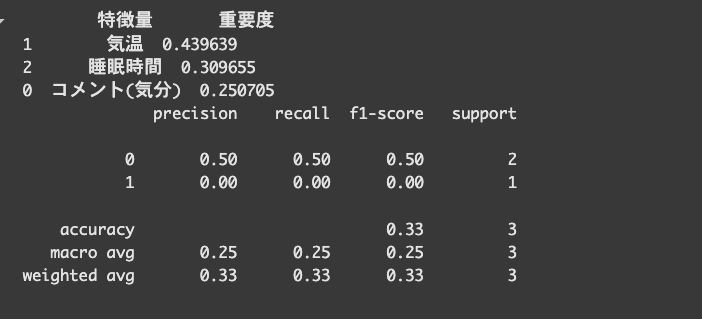
気温がおよそ44%となっており、最も体調に影響を与えているという結果になりました。
体調に影響与える要因ランキングの下にある4つの項目の意味はこちらです。
- precision(適合率):予測が当たった割合
- recall(再現率):実際の正解をちゃんと見つけられた割合
- f1-score:バランスの良いスコア
- support:各クラスのデータ数(少ないと精度が下がる)
結果、いくつか課題が見つかりました。
- テストデータが3件(support = 3)しかない → 精度の信頼性が低い
- 全体の正解率(accuracy)も 33% と低い
原因の1つとしてデータが少なすぎることが挙げられるので、
改善策として新しくデータ(30件)を追加してみます。
import torch
import pandas as pd
from transformers import pipeline, AutoModelForSequenceClassification, AutoTokenizer
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report
import numpy as np
# モデルとトークナイザの読み込み
model = AutoModelForSequenceClassification.from_pretrained('christian-phu/bert-finetuned-japanese-sentiment')
tokenizer = AutoTokenizer.from_pretrained('christian-phu/bert-finetuned-japanese-sentiment', model_max_length=512)
# パイプラインの設定
nlp = pipeline('sentiment-analysis', model=model, tokenizer=tokenizer, truncation=True)
# コメントリスト(既存+追加分)
texts = [
"新しい洋服を買えて、嬉しい", "ジムに行って筋トレできるくらい元気だった", "強い日差しで頭が痛い",
"昨日の疲れもあり帰宅後3時間お昼寝した", "勉強が盛り上がって楽しかった", "嬉しいことがあったため、今週1番テンション高かった",
"今日は久しぶりの雨で体調崩した", "風邪を引いて苦しい", "ジムで体を動かしてリフレッシュできた",
"勉強に集中できなかった", "体がだるかったが少し運動して気分転換した", "勉強が順調で、やる気が少しずつ戻ってきた",
"勉強に集中できた", "気分も安定していて、軽い運動もできてよかった", "生理と疲労が重なり、頭痛もあって辛い一日だった",
"仕事や運動もこなせて、気持ち的にも落ち着いていた", "強い頭痛とだるさで、ほぼ一日中横になっていた",
"軽く体を動かしたが、疲れが取れきれない感じだった", "勉強が進み、達成感があって良い一日だった",
"睡眠はやや短めだったが、安定して過ごせた", "気分が良く、軽い運動や仕事もスムーズにできた",
"疲労感が強く、体も重く感じた一日だった", "睡眠がしっかり取れて、少し元気を取り戻した",
"強い日差しと体調不良で、だるさが続いた", "少し疲れはあったが、ゆったり過ごせた",
"睡眠が浅かったが、勉強はなんとか進めた", "安定して過ごせたが、疲れが少し残った",
"気分も体調も安定して、スムーズに動けた", "疲れと体調不良が重なり、辛い一日だった", "今日は元気だった",
# 追加30件
"朝から体調が優れず仕事を休んだ", "快晴で気分が良く、散歩に出かけた", "熱が出て寝込んだ",
"新しい本を読んでリフレッシュできた", "花粉症がつらい", "家族と食事して楽しかった",
"頭が重くてやる気が出ない", "映画を見て元気が出た", "頭痛が続いていたが、午後には落ち着いた",
"集中力が戻ってきた", "夜更かししてしまって眠い", "リモートワークで気楽だった",
"ずっと家にいたので運動不足", "カフェで勉強できて満足", "だるさはあるが気分は前向き",
"音楽を聴いてリラックスできた", "腹痛があり一日中つらかった", "瞑想してリフレッシュできた",
"体調は微妙だったけど、何とかやり過ごせた", "同僚と話して少し元気が出た", "めまいがして少し休んだ",
"食欲がなくてほとんど食べられなかった", "友達とゲームして楽しかった", "目の疲れがひどい",
"朝日を浴びて気分が晴れた", "やることが多くて少し疲れた", "鼻づまりがひどくて眠れなかった",
"リズムよく作業が進んだ", "何となく気が沈んでいた", "コーヒーが美味しくて幸せだった"
]
labels = []
# 感情分析の実行
for text in texts:
inputs = tokenizer(text, padding=True, truncation=True, return_tensors='pt', max_length=512)
outputs = model(**inputs)
logits = outputs.logits
probabilities = torch.softmax(logits, dim=1)[0]
sentiment_label = model.config.id2label[torch.argmax(probabilities).item()]
if sentiment_label == 'positive':
labels.append(0)
elif sentiment_label == 'negative':
labels.append(-1)
else:
labels.append(1)
# データ作成
data = {
"コメント(気分)": labels,
"日付": [f"4/{i+17}" for i in range(30)] + [f"5/{i+17}" for i in range(30)],
"気温": np.random.uniform(16, 28, 60).round(1).tolist(),
"睡眠時間": np.random.uniform(5, 9, 60).round(1).tolist(),
"体調不良": [1 if l == -1 else 0 for l in labels]
}
df = pd.DataFrame(data)
# モデル学習と評価
X = df[['コメント(気分)', '気温', '睡眠時間']]
y = df['体調不良']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.1, random_state=42)
model = RandomForestClassifier(random_state=42)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
# 特徴量の重要度
importances = model.feature_importances_
feature_importance = pd.DataFrame({
'特徴量': X.columns,
'重要度': importances
}).sort_values(by='重要度', ascending=False)
print(feature_importance)
print(classification_report(y_test, y_pred))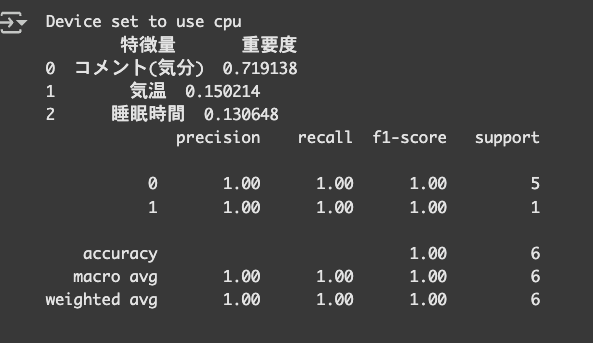
こちらでは、コメント(気分)が最も体調に影響を与えているという結果になりました。
ネガティブな感情表現がある時は、体調を崩しやすくなる傾向があるということがわかりました。
精度ですが、テストデータ(6件)に対して100%の精度で予測できており、
ランダムフォレストが特徴量(コメント・気温・睡眠時間)から体調不良をうまく判定できていることがわかります。
ランダム生成の部分の説明:
①日付
"日付": [f"4/{i+17}" for i in range(30)] + [f"5/{i+17}" for i in range(30)],こちらは日付のリストを自動で作っている部分です。
前半の [f"4/{i+17}" for i in range(30)] は、4/17 から 4/46 までの30日分を生成。
後半の [f"5/{i+17}" for i in range(30)] は、5/17 から 5/46 までの30日分を生成。
結果的に 60個の日付文字列(4月と5月)になります。
※ 日付の「46日」とかは実際には存在しない日付です。このコードは日付のフォーマットだけをラベルとして使っているので、厳密なカレンダーの日付ではありません。
② 気温
"気温": np.random.uniform(16, 28, 60).round(1).tolist(),np.random.uniform(16, 28, 60)では、16度以上28度未満の実数を60個ランダムに生成します。
.round(1)では、 小数第1位まで四捨五入(例:23.2)しています。
.tolist()は、NumPy配列からPythonのリストに変換します。
③睡眠時間(5〜9時間の範囲でランダムに生成)
"睡眠時間": np.random.uniform(5, 9, 60).round(1).tolist(),こちらも同様に、5〜9時間の実数値をランダムに60個生成しています。
④体調不良
体調不良": [1 if l == -1 else 0 for l in labels]これは「体調不良かどうか」を 0 or 1 に変換しています。
labels には -1, 0, 1 のどれか(negative, neutral, positive)が入っていて、
-1(ネガティブ)だったら体調不良とみなして 1、それ以外は 0 としています。
まとめ
今回の分析では、気分コメントや気温、睡眠時間から体調不良を予測してみました。
結果、「コメントの感情」が一番影響しているっぽいことが分かりました。
今後は歩数や食事の内容なんかも取り入れて、もっと精度の高い体調予測ができるようにしていけたらと思ってます。
ありがとうございました!
※今回は一部ランダムなデータも使っているので、本格的には実際の記録で検証が必要です。

コメント