
はじめに
お疲れ様です🍒
今日は、前回の投稿に引き続き「美容商品の販売データ」を使ったコーディングをしていきます。
本記事では、APIから気象データを取得し、前回作成したデータフレームと統合するところまでを解説します。
よろしくお願いいたします🙇♀️
【使用したAPI】
サイト名:OpenWeatherMap
サイトリンク:https://openweathermap.org
詳細内容:
| 項目 | 内容・制限 |
| コアモデル | WeatherNext 2 (DeepMind製 AIモデル) |
| 提供形態 | Google Maps Platform Weather API |
| 更新頻度 | 1日4回(6時間ごと)の予測生成、1時間ごとの更新 |
| 無料枠 (Free) | 1分あたり 60リクエスト まで(月間の無料枠内) |
| 予報範囲 | 3時間ごとの予報:最大5日間 |
| 取得可能データ | 気温、降水確率、風速・風向き、湿度、UV指数、雷確率など |
【環境】
- OS:MAC
- パッケージ・プロジェクトの管理ツール:poetry
- 言語:Python
- データベース:DuckDB
前回の投稿✨↓

よろしくお願いいたします!
コードの解説
全体のコードはブログの一番下にまとめてあります。
都度確認しながら読み進めてみてください。
◾️実行用の関数を呼び出す
まず、get_weather関数を呼び出します。
APIを呼び出し、気象データの取得を行います。
(※前回の投稿でrun_analysis関数は解説済み)
引数には、欲しいデータの県名を入れます。
main.py
data = get_weather("Tokyo")
◾️APIキーを取得する
get_weather関数はweather_api_client.pyで管理しています。
weather_api_client.py
load_dotenv()
API_KEY = os.getenv("OPENWEATHER_API_KEY")
def get_weather(city_name):
if not API_KEY:
print("APIKEYが指定されてません")
return
url = f"https://api.openweathermap.org/data/2.5/forecast?q={city_name}&appid={API_KEY}&units=metric&lang=ja"
API_KEYはセキュリティ保護のためenvファイルで管理します。
.env
OPENWEATHER_API_KEY=任意のAPIキー
.envからAPIキーを読み込みます。
weather_api_client.py
load_dotenv()
APIキーが認識できたら、URLを読み込みます。
{city_name}には引数のTokyo,{API_KEY}にはAPIキーが自動で設定されます。
◾️APIにリクエスト申請を送る
weather_api_client.py
try:
response = requests.get(url)
response.raise_for_status()
data = response.json()
return data
except Exception as e:
print(f"エラーが発生しました:{e}")
まず、指定したURLに対して「データをください!」とリクエストを送り、返ってきた結果を変数に保存します。
response = requests.get(url)
urlが間違っていたり、サーバーが落ちていたらエラーを出します。
response.raise_for_status()
返ってきた生データをJSON形式に変換します。
JSON形式にするとPythonの「辞書型」や「リスト型」などに変換でき、簡単に中身を扱えるようになります。
data = response.json()
気象データがJSON形式で取れました。
{
"cod": "200",
"message": 0,
"cnt": 40,
"list": [
{
"dt": 1800000000,
"main": {
"temp": 18.5,
"feels_like": 17.2,
"temp_min": 16.0,
"temp_max": 20.5,
"pressure": 1013,
"sea_level": 1013,
"grnd_level": 1010,
"humidity": 45,
"temp_kf": 0.5
},
"weather": [
{
"id": 800,
"main": "Clear",
"description": "快晴",
"icon": "01d"
}
],
"clouds": { "all": 0 },
"wind": {
"speed": 3.4,
"deg": 210,
"gust": 4.8
},
"visibility": 10000,
"pop": 0,
"sys": { "pod": "d" },
"dt_txt": "2026-05-10 12:00:00"
},
{
"dt": 1800010800,
"main": {
"temp": 15.2,
"feels_like": 14.8,
"temp_min": 14.5,
"temp_max": 16.0,
"pressure": 1015,
"sea_level": 1015,
"grnd_level": 1012,
"humidity": 55,
"temp_kf": -0.2
},
"weather": [
{
"id": 801,
"main": "Clouds",
"description": "晴れ(雲少なめ)",
"icon": "02n"
}
],
"clouds": { "all": 20 },
"wind": {
"speed": 2.1,
"deg": 180,
"gust": 3.0
},
"visibility": 10000,
"pop": 0.1,
"sys": { "pod": "n" },
"dt_txt": "2026-05-10 15:00:00"
}
]
}
※著作権や規約の関係で、ダミーデータに変換しています。
◾️データフレーム(表)を作る
API経由で取得した気象データからデータフレームを作成します。
main.py
weather_df = create_weather_frame(data)
create_weather_frame関数はmain.pyで管理しています。
main.py
def create_weather_frame(data):
weather_list = []
for forecast in data['list']:
weather_list.append({
"Date_Time":forecast['dt_txt'],
"Weather":forecast['weather'][0]['description'],
"Temp_Celsius":forecast['main']['temp']
})
return pd.DataFrame(weather_list)
まず、処理結果を保存・管理するリストを作ります。
Date_Time(日付)とWeather(天気)とTemp_Celsius(気温)のデータをリストに追加します。
そして、pandasのDataFrame関数を使い、weather_listをデータフレームに変身させます。
出力結果:
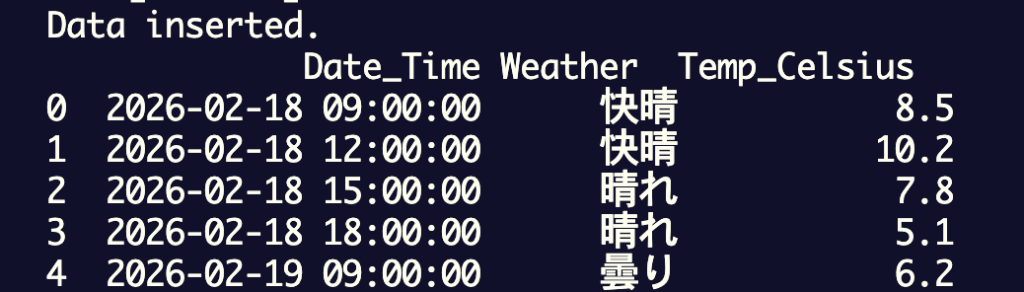
◾️データの統合
最後に、美容商品の販売データと気象データを統合します。
[結合キー]
・美容商品の販売データ:SALE_DATE
・気象データ:Date_Time
main.py
df_combined = pd.merge(
product_df,
weather_df,
left_on='SALE_DATE',
right_on='Date_Time',
how='left')
出力結果:

エラーメッセージ:
ValueError: You are trying to merge on datetime64[us] and str columns for key 'SALE_DATE'. If you wish to proceed you should use pd.concat
Google翻訳:
ValueError: キー 'SALE_DATE' の datetime64[us] 列と str 列をマージしようとしています。続行するには、pd.concatを使用してください。
pd.concatを使用すると、行番号を並べてがっちゃんこするだけで日付の整合性は無視されるような気がするため、mergeのままで行きたいです。
(pd.concatで日付の整合性取る方法があれば教えてほしいです)
ということで、merge関数を使うために結合キーの形式を統一する方向でコードの改修を行います。
◾️結合キーの型や表示形式の調査と変換
まず、結合キーの型や表示形式がどうなっているのか調べてみます。
main.py
# 型の確認
print(product_df['SALE_DATE'].dtype)
print(weather_df['Date_Time'].dtype)
# 結合キーの値を数件表示して見比べる
print(product_df['SALE_DATE'].head())
print(weather_df['Date_Time'].head())
出力結果:
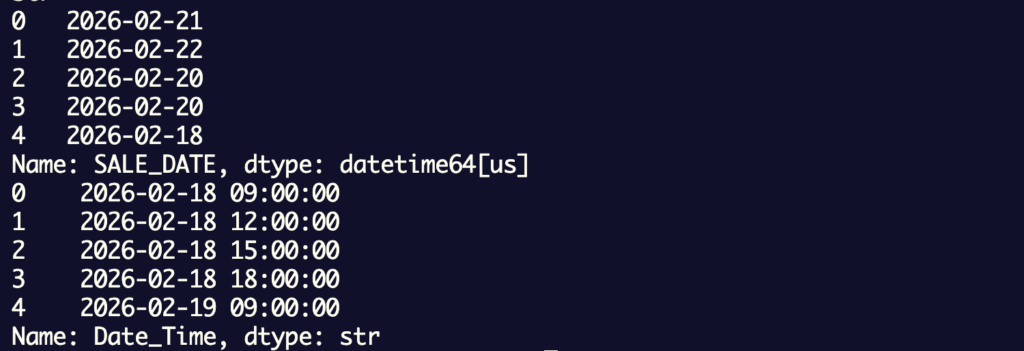
| データソース | 項目名 | dtype | 形式 | 課題 |
| 美容販売データ | SALE_DATE | datetime64 | YYYY-MM-DD | 特になし |
| 気象データ | Date_Time | str (object) | YYYY-MM-DD hh:mm:ss | 型と粒度が不一致 |
日付のデータは、美容商品の販売データのSALE_DATEに統一します。
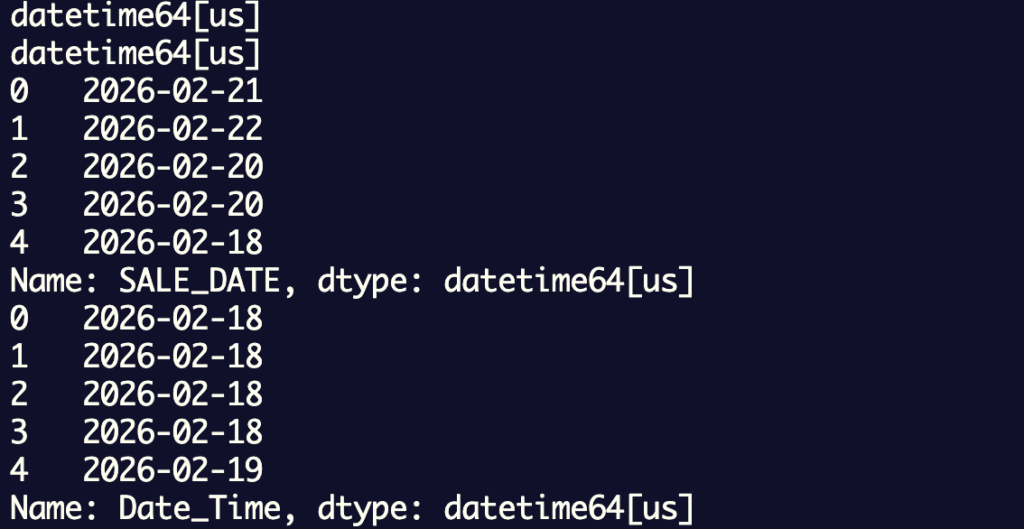
weather_dfの型をdatetime64に、日付の表示形式はYYYY-MM-DDに変えます。
main.py
# strをdatetime64に変換
weather_df['Date_Time'] = pd.to_datetime(weather_df['Date_Time'])
# 時刻を00:00:00にリセット(normalize)して日付の粒度を揃える
weather_df['Date_Time'] = weather_df['Date_Time'].dt.normalize()
出力結果:無事に型と日付の表示形式統一されました。
再度、データを統合した結果も見てみましょう。
出力結果:
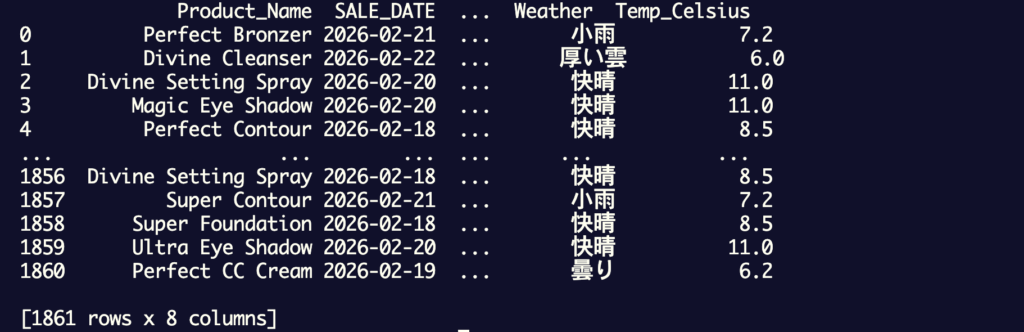
データが統合されました。嬉しい!
分析してみよう
1.どの天気が多かったのか、天気ごとのデータ件数を確認します。
main.py
print(df_combined['Weather'].value_counts())
出力結果:

快晴の件数が最も高く、続いて晴れの件数が多い傾向にあるみたいですね。
2.基本統計量(気温の平均や中央値)を確認します。
main.py
print(round(df_combined['Temp_Celsius'].describe()),2)
出力結果:
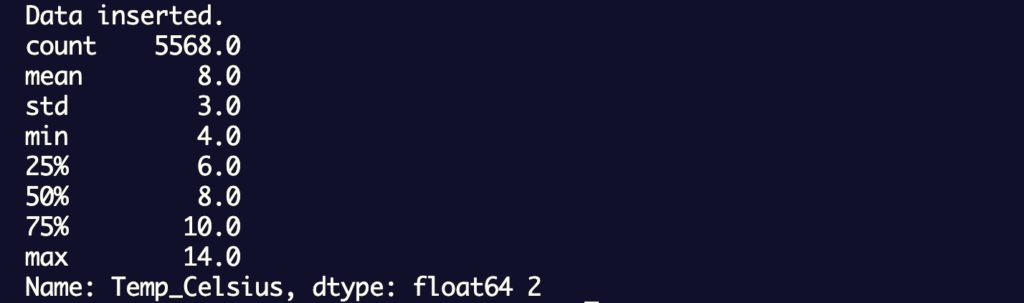
気温の平均値は8.0度、最低気温は4.0度、最高気温は14.0度になっていますね。
3.気温による売れ筋商品の変化
「5度以下の寒い日」と「10度以上の暖かい日」で、売れている商品のランキングがどう変わるかを比較します。
main.py
df_combined['Temp_Category'] = pd.cut(df_combined['Temp_Celsius'], bins=[-float('inf'), 7, float('inf')], labels=['寒い', '暖かい'])
print(df_combined.groupby(['Temp_Category', 'Product_Name']).size().unstack())
出力結果:

Ultra Setting Spray(セッティングスプレー):
- 寒い:4件
- 暖かい:22件
暖かい日の方が「メイク崩れ」を気にする人が多く、スプレーの需要が5倍以上に跳ね上がっている可能性があるかもしれません。
Divine Blush(チーク):
- 寒い:19件
- 暖かい:32件
暖かい日は外出機会が増え、フルメイクをする人が多いため全体的に売上が伸びているのかもしれませんね。
おわりに
今回は
APIから気象データの取得し、商品販売データと統合しました。
ブログで紹介した分析は、基本的な集計のみでしたが、データにはまだまだ面白い発見が眠っていそうです。
引き続き自分なりの切り口でこのデータの奥深さを探求できたらなと思います。
ありがとうございました🙇♀️
今回登場したコード全体
main.py
import src.db_util as util
import src.table_category as conf
import src.create_table as create_table
import src.insert_data as insert_data
import pandas as pd
from src.weather_api_client import get_weather
def run_analysis():
con = util.get_connection()
create_table.run(con)
insert_data.run(con)
sql_path = "src/sql/analysis_beauty_product.sql"
query = util.read_sql_file(sql_path)
formatted_query = query.replace("{TABLE_BEAUTY_BASIC_INFO}", conf.TABLE_BEAUTY_BASIC_INFO) \
.replace("{TABLE_BEAUTY_DETAILS_INFO}", conf.TABLE_BEAUTY_DETAILS_INFO)
df = con.execute(formatted_query).df()
return df
def create_weather_frame(data):
weather_list = []
for forecast in data['list']:
weather_list.append({
"Date_Time": forecast['dt_txt'],
"Weather": forecast['weather'][0]['description'],
"Temp_Celsius": forecast['main']['temp']
})
return pd.DataFrame(weather_list)
if __name__ == "__main__":
product_df = run_analysis()
data = get_weather("Tokyo")
weather_df = create_weather_frame(data)
# strをdatetime64に変換
weather_df['Date_Time'] = pd.to_datetime(weather_df['Date_Time'])
# 時刻を00:00:00にリセット(normalize)して日付の粒度を揃える
weather_df['Date_Time'] = weather_df['Date_Time'].dt.normalize()
# 型の確認
# print(product_df['SALE_DATE'].dtype)
# print(weather_df['Date_Time'].dtype)
# 結合キーの値を数件表示して見比べる
# print(product_df['SALE_DATE'].head())
# print(weather_df['Date_Time'].head())
df_combined = pd.merge(
product_df,
weather_df,
left_on='SALE_DATE',
right_on='Date_Time',
how='left')
print(df_combined)
print(df_combined['Weather'].value_counts())
print(round(df_combined['Temp_Celsius'].describe()),2)
df_combined['Temp_Category'] = pd.cut(df_combined['Temp_Celsius'], bins=[-float('inf'), 7, float('inf')], labels=['寒い', '暖かい'])
print(df_combined.groupby(['Temp_Category', 'Product_Name']).size().unstack())
weather_api_client.py
import requests
from dotenv import load_dotenv
import os
load_dotenv()
API_KEY = os.getenv("OPENWEATHER_API_KEY")
def get_weather(city_name):
if not API_KEY:
print("APIKEYが指定されてません")
return
url = f"https://api.openweathermap.org/data/2.5/forecast?q={city_name}&appid={API_KEY}&units=metric&lang=ja"
try:
response = requests.get(url)
response.raise_for_status()
data = response.json()
return data
except Exception as e:
print(f"エラーが発生しました:{e}")